My first deep learning project! I wanted to embark on a journey into artificial neural networks with a challenging project requiring image classification. The end product involves a simple application utilizing a complex neural network to track a user's emotions through their webcam. I developed and trained a convolutional neural network (CNN) to classify an image of a face as either happy, sad, or neutral. After lots of research and refactoring, I was able to use Pytorch to create a model that performed with 80% accuracy on my validation set. This project has provided me with a lot of hands-on experience with creating accurate CNN models. Specifically, I gained a deep understanding of the importance of crafting a high-quality training dataset to improve model performance, and explored the bias-variance tradeoff and its critical role in balancing underfitting and overfitting. I also learned about techniques such as pooling layers, regularization, and normalization to effectively mitigate overfitting, along with their tradeoffs between model accuracy and the application of these methods. This was a very fun and rewarding project, and has opened me up to the supreme potential of deep-learning software.
Halma is a board game similar to checkers. The main differences between the two games is that in Halma pieces can not be taken, the goal is instead to get all of your pieces to the opposite corner before your opponent. Piece movement in Halma also differs because pieces can move in any direction and can perform sequential jumps in varying directions. A more in depth explanation of Halma rules can be found here.
The halma gameplay is made possible by a Python user-interface library called Tkinter. This library allows us to create a graphical UI window that a user can interact with. The artificial intelligence controlling the black pieces is derived from the minimax algorithm. This is a recursive algorithm commonly used in two player games. It works by evaluating possible moves by simulating all potential future game states and choosing the move that maximizes its chances of winning and/or minimizes the opponent's chances.
DBSCAN Algorithm
(Density-Based Spatial Clustering of Applications with Noise)
I was proudly the lead developer for this group project. This unsupervised learning algorithm is able to cluster (group) data in any dataset based on their dimensional distance from one another. Because of the millions of points that the average datasets contain, we utilized the speed and parallelism of the GPU through Cuda programming. Multiple optimizations were made to maximize our kernel's runtime performance.
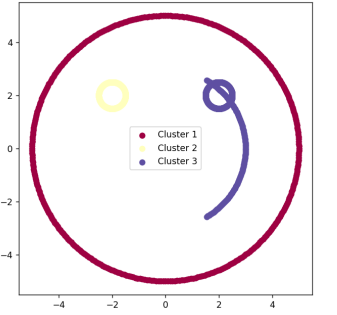
The neat thing about this algorithm is that it's not only applicable to simple 2-dimensional datasets like the one displayed to the right. It can be used to cluster any CSV dataset, including images and videos (with millions of dimensions)! We tested and applied our DBSCAN implementation to identify star clusters from a dataset of star locations, and areas of intense snow from a dataset containing the snowfall of different regions. Please take the time to view our final report which outlines everything about this project including our implementation technique.
Operating System Simulation
This simulator project was written in the C language, and is one of the most intricate and complex solo projects I have completed thus far. This program takes in randomized metadata and simulates how an operating system handles processes, device IO, and memory requests.
This program can run preemptively meaning processes can be interrupted by higher-priority processes, accurately reflecting how single-core CPUs work. A good example of preemption in my simulator is context-switching: When a process makes (and waits for) a request, the CPU will save the state of that process and begin working on the next scheduled process. This speeds up the execution time, for the CPU is only idle when all processes are blocked. When ran non-preemptively on the other hand, all processes are uninterrupted and execute in their scheduled order.
My simulator follows an inputted scheduling algorithm. The options are: FCFS-N (first come first served non-preemptive) FCFS-P (first come first served preemptive) SJF-N (shortest job first non-preemptive) SRTF-P (shortest remaining time first preemptive) RR-P (round robin scheduling)
Download the code here and run in a linux terminal. Feel free to change things around in the configuration and metadata files.
DendroDoggie Application
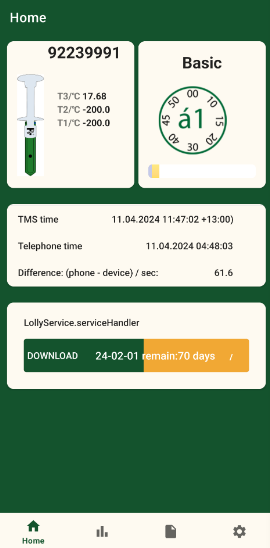
This project was for my senior capstone and turned out to be a big success for our clients. We created an Android application that provides a single interface to download, visualize, organize, and store data outputted from devices created by the well-known TOMST company. These devices include the dendrometer which measures tree growth through a compression pin, and the TMS-4 which reads soil moisture. Both of these devices also take temperature measurements to show the relationship between climate and these variables.
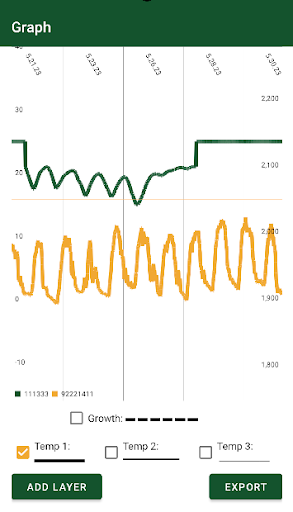
As the Back-end developer for the group, I oversaw the full lifecycle of this application's functionality. My main contributions included translating the raw CSV data into two-dimensional line charts, and the ability to merge CSV data in order to visualize multiple datasets on the same chart plane.
Our poster for the NAU undergraduate Engineering Fest can be found here. Please download the APK for the DendroDoggie application, and test it out!
This was a solo project which was later utilized by my group for the DBSCAN algorithm above. Similarly, this program was written in Cuda so that we can utilize the speed of the GPU for large datasets. A similarity search concerns comparing different values in a dataset that may seem to have too many components to be comparable. How similar are two birds? As simple minded humans we generally will compare two birds based on a single or a few characteristics such as maybe color and size. My algorithm differs because it compares two things based on all of their attributes (columns), which is not always feasible for human calculation, especially with complex objects.
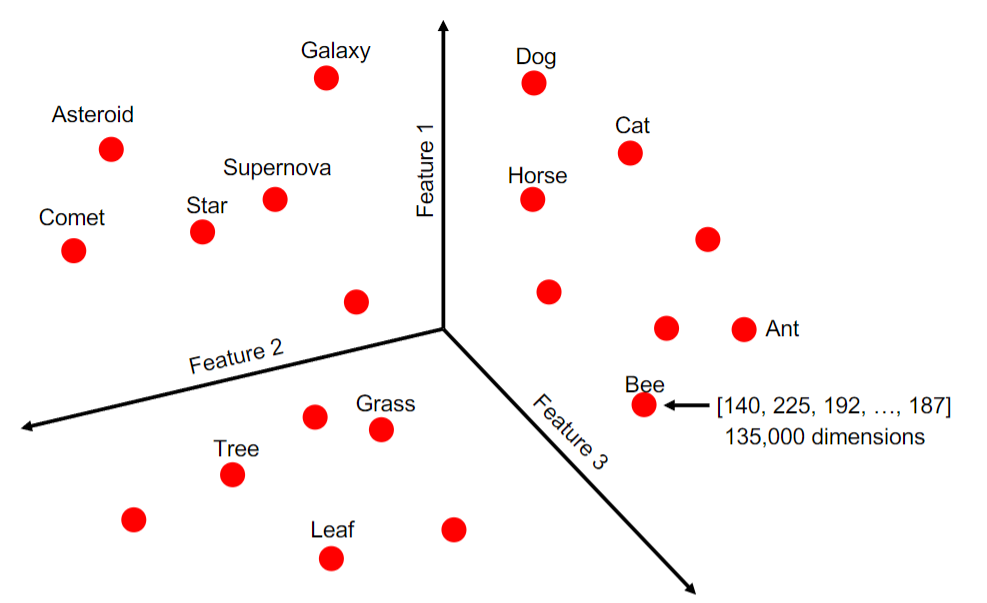
My similarity search was tested on a dataset of bee images (7,490 images, each with 45,000 pixels). Each pixel of the image has 3 values representing a RGB value. This brings the total dimensions of each image to 135,000! My algorithm utilizes a distance matrix in order to compare the difference of each RGB value, of each pixel, of each photo.
For each image, the program determines the number of images that have distances within a provided epsilon value. In simpler terms, the program finds how many photos are similar to a given photo. Download the code here and run on a device with a GPU.
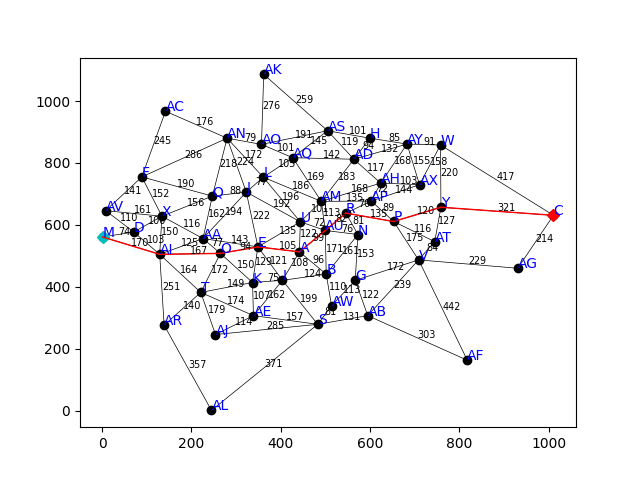
Route Searcher
The aim of this programming exercise is to explore the implications of different search algorithms and heuristics in a nice, easily-vizualized route-finding domain. Specifically, the challenge is to implement a general search engine program capable of doing DFS, BFS, Best-first, and A*.
My route finder works off of a map file containing the information of each edge, following the form:
(node1, node2, edgevalue, [x1,y1],[x2,y2])
Given start and end nodes, the program follows the provided search algorithm to find a route to the end node. For this project, I utilized Python classes to keep the code organized and modular, allowing for a better separation of concerns.
I used this program to test each of these algorithms to better understand their strengths and weaknesses. A* and Best will obviously always outperform BFS and DFS becauing they are completely uninformed searches with no heuristics to guide them. When we must search an unweighted graph blindy, when would an agent utilize Breadth-First vs Depth-First? This divides the concerns of optimality and efficiency. If memory efficiency is a priority, then it is likely best to utilize DFS, espcially for longer routes. Breadth-First is very memory intensive, storing all children of each node in a massive queue. Because of this, BFS is more likely than DFS to produce an optimal path, but should only be considered for shorter routes of lightly-connected graphs.
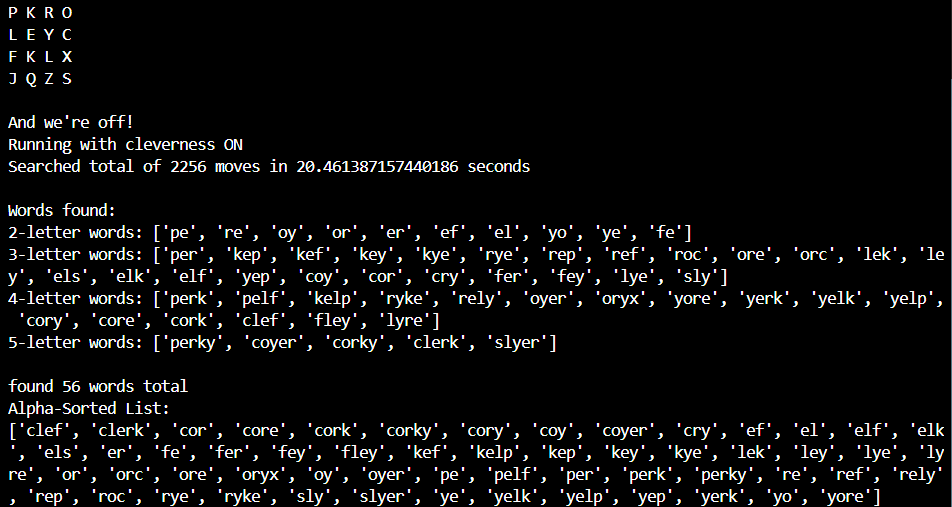
Boggle Solver
This was a fun Python implementation that dives into the world of recursive searching. Boggle is a game that challenges a player to connect adjacent letters to form words. My Python program can search any size of NxN boggle board and list all possible words achievable. A 4x4 boggle board contains more than 12 million distinct paths, making runtime optimizations essential. I was able to achieve a speedup of 60X over my base implementation that searches each and every possible path on the board.
Code can be accessed here along with a writeup explaining the implementation.
Some of the words found in my output on the right may seem strange or unfamiliar, but trust that they are indeed words present in the dictionary file used to run this program!